
As developers take on more and larger issues, they must store their data in increasingly sophisticated ways, which necessitates the employment of a constellation of computers to hold it all.
However, adding extra computer hardware might cause confusion when different sections of the network must be contacted for a certain query, especially when data requests are frequently made quickly. Before a database change can be completed, it must be disseminated to all computers – which may be spread across several data centres.
Complex data requires complex solutions
When developing apps, developers like to have a “single source of truth,” or a record of critical data. This should be able to provide them with the most up-to-date information at any time.
It’s straightforward to achieve this consistency with just one machine running a database. Defining a single version of the truth while multiple computers are executing in parallel might be difficult. When two or more modifications come on distinct computers in quick succession, the database has no easy means of knowing which came first.
When computers do tasks in milliseconds, the sequence in which these changes occur might be unclear, requiring the database to decide who receives the aircraft seat or concert tickets.
The problem gets worse as the number of jobs allocated to a database rises. Large databases that span many machines are becoming increasingly common in tasks. To enhance response time and offer distant redundancy, these computers may be placed in multiple data centres across the world. However, when database updates come in quick succession on various computers, the added communication time required substantially increases complexity.
And turning everything over to a high-end cloud service won’t fix the problem. When it comes to consistency, database services from behemoths like Amazon AWS, Google Cloud, and Microsoft Azure all have limitations, and they may provide numerous variants to select from.
To be sure, certain occupations are unaffected by this issue. Many applications like KaraStar APK simply ask that databases keep track of variables that are slowly changing and unchanging, such as the size of your monthly electricity bill or the winner of last season’s baseball games. The data is saved once, and all subsequent queries will receive the same response.
Other duties, such as keeping track of the number of available seats on an airline, might be challenging. If two individuals try to purchase the final ticket on a plane, they may each receive a response stating that only one seat is available. The database must go above and above to verify that each seat is only sold once. (The airline may still choose to overbook a flight, but this is a business choice rather than a database error.)
When the changes are complex, databases work hard to preserve consistency by combining several changes into discrete packages known as “transactions.” If four persons travelling together request tickets on the same aircraft, for example, the database may keep the group together and only process changes if there are four vacant seats available.
In many situations, database designers must choose whether or not to sacrifice consistency for performance. Is maintaining high consistency worth delaying updates until they reach every part of the database? Is it preferable to forge on because the chances of any irregularity causing a serious problem are slim? Is it really so terrible if someone purchases a ticket five milliseconds later than someone else? It’s probable that no one will figure it out.
The issue only manifests itself during the brief period of time it takes for fresh copies of data to travel throughout the network. The databases will converge on a correct and consistent answer.
Several “eventually consistent” versions are currently supported by various databases. The conundrum of how to effectively tackle the situation has been thoroughly researched throughout the years. The CAP theorem, which defines the tradeoff between consistency, availability, and partition ability, is popular among computer scientists. It’s typically simple to pick any two of the three, but it’s more difficult to integrate all three into a single functional system.
Why is eventual consistency important?
The concept of eventual consistency arose as a method to temper accuracy expectations when it was most difficult to meet. This occurs shortly after new data has been written to a single node but has not yet been disseminated throughout the network of machines that store the data. Database developers frequently strive to be more explicit by laying out the various levels of consistency that they may provide. Werner Vogels, Amazon’s chief technology officer, outlined five distinct versions that the company explored when developing some of the databases that underpin Amazon Web Services (AWS). Versions such as “session consistency,” which guarantees consistency but only within the context of a single session, are on the list.
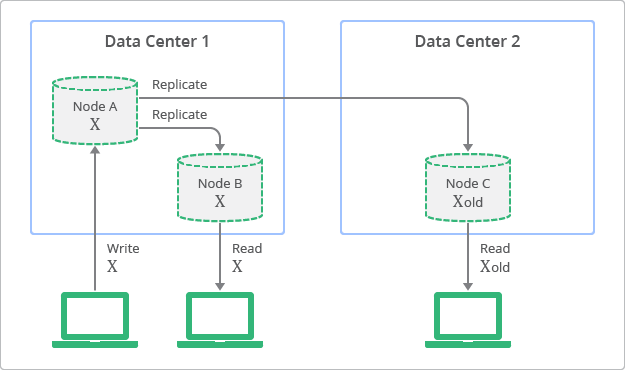
Because many NoSQL databases began by promising merely eventual consistency, the concept is intimately linked to them. Database designers have researched the topic in more depth throughout time and built improved models to more precisely represent the tradeoffs. Some database administrators, particularly those who wear both belts and suspenders to work, are still troubled by the concept, although users who don’t want precise replies like the quickness.
What are the upstarts doing?
Many new NoSQL database systems expressly support eventual consistency to make development easier and faster. The companies may have started with the most basic approach for consistency, but they’ve since expanded their choices for developers to trade-off sheer speed for greater accuracy when it’s needed.
Cassandra, one of the first NoSQL databases, now supports nine write reliability choices and ten read uniformity options. Developers might choose to sacrifice speed for consistency depending on the needs of the application.
Couchbase, for example, provides a “tunable” level of consistency that may be adjusted from query to query. MongoDB can be set up to provide eventual consistency for read-only replicas for speed, but it can also be set up with a number of settings to provide more reliable consistency. PlanetScale proposes a paradigm that strikes a compromise between consistency and speed, suggesting that banks aren’t the only ones who struggle with inconsistency.
Some businesses are developing new processes to get them closer to achieving great consistency. To synchronize the versions operating in separate data centres, Google’s Spanner, for example, relies on an extremely precise system of clocks. These timestamps may be used by the database to determine which fresh block of data came first. FaunaDB, on the other hand, employs a variant of a system that does not rely on extremely precise timekeeping. Instead, the firm produces artificial timestamps to aid in deciding which version of conflicting data to maintain.
Yugabyte has opted to accept the CAP theorem’s consistency and partition ability in exchange for availability. Until the database achieves a consistent state, certain read requests will halt. CockroachDB employs a paradigm that, according to the company, provides a serialized but not linearized version of the data.
The limits of eventual consistency
Users are willing to wait for responses that are consistent for essential activities, such as those requiring money. Consistent models may eventually become acceptable for many data gathering activities, but they aren’t suitable for tasks requiring a high level of confidence. When businesses can afford to maintain huge machines with plenty of RAM, databases with high consistency are ideal for organizations in charge of limited resources.




